Usando Selenium e Python para fazer scraping
Scraping é a obtenção de dados de forma automatizada de páginas web e pode ser útil para uma porção de coisas, como por exemplo, acompanhar manchetes em determinadas páginas diariamente.
Dentre as ferramentas que possibilitam scraping, Selenium - aqui como um pacote do Python - é popular, intuitiva e com apenas algumas de suas funções é possível fazer a maior parte do trabalho.
Neste tutorial, usaremos Selenium aplicado ao navegador Firefox, ou seja, Selenium fará o scraping por meio de abas no Firefox.
Requisitos
editarPara rodar o scraping, é necessário:
- Python, a linguagem de programação.
- Selenium, a biblioteca de Python.
- Firefox, o navegador.
- Geckodriver, o driver que permite que comandos em Selenium sejam compreendidos pelo Firefox.
Selenium
editarPara instalar Selenium, basta usar o gerenciador de bibliotecas do Python, o pip:
pip install selenium
Firefox
editarNo Firefox, é recomendável criar um novo perfil exclusivo para o scraping. Para isso, visite about:profiles no navegador e crie um novo perfil.
Esse perfil conterá algumas informações, como nome, pasta raiz e pasta local. O Selenium precisará da pasta raiz para abrir o perfil desejado.
Geckodriver
editarPara instalar o Geckodriver é necessário baixá-lo e instalá-lo na sua máquina. Há tutoriais[1] que explicam como instalá-lo.
Note que o mais fácil e menos recomendado é apenas mover o executável geckodriver para /usr/local/bin. Isso facilita a execução dos scripts mas não é uma prática segura. O melhor é explicitar dentro do script em Python o caminho pro geckodriver [2].
O Poder do XPath
editarUma das ferramentas mais poderosas para minerar dados de páginas web é o XPath [3]. Com ela, podemos identificar elementos na página de inúmeras maneiras.
É recomendado praticar e aprender como usar XPath se você deseja fazer scraping. XPath nada mais é do que uma query, ou um comando que encontra caminhos na página.
Você precisará dos XPath para que o Selenium encontre os dados desejados. Uma forma rápida de testar caminhos XPath é abrir o modo inspetor num navegador (Ctrl + Shift + i), abrir o console e digitar:
$x("<xpath_procurado>")Neste tutorial haverá alguns exemplos de uso de XPath.
Executando o Scraping
editarAgora, com as instalações prontas, podemos executar nossos scripts.
Crie um arquivo .py e importe as seguintes bibliotecas relevantes:
from time import sleep
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
Feito isso, é necessário abrir o Driver que irá interagir com o navegador. Note que esse Driver pode ser passado entre funções como uma variável qualquer. Dessa forma, o mais adequado é criar uma função que retorne o Driver configurado. Note também que essa função funciona caso seu executável geckodriver esteja em /usr/local/bin.
def abreDriver():
ffOptions = Options()
ffOptions.add_argument("-profile")
ffOptions.add_argument(r'/home/user/.mozilla/firefox/imd44bm.selenium') #Aqui é fornecida a pasta raiz do perfil do Firefox
driver = webdriver.Firefox(options=ffOptions)
return driver
Pronto, já temos como configurar nosso driver sempre que precisarmos executar o script.
Exemplo 1
editar-
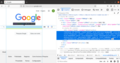 Elemento 'textarea' destacado no modo inspetor
Elemento 'textarea' destacado no modo inspetor

Agora, podemos começar o scraping. A primeira função que criaremos realiza o seguinte processo:
- Abre a página inicial do Google.
- Envia uma pesquisa e aperta Enter.
- Obtém e imprime os links principais que o Google fornecer.
A seguir o código:
def obter_links_do_google(driver):
driver.get("https://www.google.com/")
sleep(15)
termo_busca = "uol"
barra_busca = driver.find_element(By.TAG_NAME, "textarea")
barra_busca.send_keys(termo_busca)
barra_busca.send_keys(Keys.RETURN)
sleep(15)
links_candidatos = driver.find_elements(By.XPATH, "//h3[@class='LC20lb MBeuO DKV0Md']/parent::a")
for link in links_candidatos:
print(link.get_attribute("href"))
Note o sleep(15) nas linhas 4 e 11. Após abrir uma página, é recomendado esperar algum tempo até obter os dados ou realizar comandos. Isso evita erros de execução.
A linha 2 acessa o site desejado. Lembre-se de usar o endereço completo, incluido "http/https" e "www".
Na linha 7 usamos o recurso de encontrar elemento. No caso, o elemento que pesquisamos tem a tag "textarea". Esse elemento corresponde ao espaço de digitar a pesquisa na página inicial do Google.
Para descobrir qual elemento procuramos, abra o navegador e no modo inspetor, use (Ctrl+Shift+C) e clique no elemento desejado. Isso exibirá no inspetor os dados daquele elemento, como "class" ou "href". Identificar dados exclusivos de um elemento é fundamental para efetuar o scraping.
As linhas 8 e 9 descrevem o envio de dados pra página. Em 8 enviamos o texto a ser procurado na área de digitação e em 9 pressionamos Enter (Keys.RETURN).
Na linha 13 usamos uma pesquisa por XPath para obter os elementos contendo links. Estudando a página nota-se que cada cartão de resultado principal contém um elemento "h3" cujo dado "class" é "LC20lb MBeuO DKV0Md".
Cada elemento "h3" desse possui um elemento pai chamado "a".
Nesse XPath:
"//h3[@class='LC20lb MBeuO DKV0Md']/parent::a"As duas barras "//" representam que a busca pode começar de qualquer lugar, "h3" significa que estamos buscando por um elemento h3 e [@class='LC20lb MBeuO DKV0Md'] especifica qual tipo de "h3" estamos procurando. No caso, um "h3" que contenha uma "class" chamada 'LC20lb MBeuO DKV0Md'.
Depois de encontrados os "h3", "/parent::a" procura os pais que dele que sejam elementos "a".
Esses elementos "a" encontrados possuem um dado "href" que contém o link final que buscamos.
Para obter "href", ou seja, os links fornecidos pela busca no Google, usamos as linhas 15 e 16.
Em 16, cada dado (ou atributo) dos elementos "a" chamado de "href" é impresso. Esses são os links desejados.
O resultado da execução foi o seguinte:
https://www.uol.com.br/
https://www.youtube.com/user/uol
https://www.youtube.com/@uol
https://www.instagram.com/uoloficial/?hl=pt-br
https://pt.wikipedia.org/wiki/Universo_Online
Exemplo 2
editarNo exemplo a seguir, acessamos um site de notícias e usamos XPaths para obter as principais manchetes do tema esporte e as imprimimos.
O código:
def manchetes_secundarias_esporte(driver):
driver.get("https://www.uol.com.br/")
sleep(15)
manchetes_esporte = driver.find_elements(By.XPATH, "//section[@data-key='esporte']//h3[@class='title__element headlineSub__content__title']")
for elemento in manchetes_esporte:
print(elemento.text)
Aqui não há nada novo. Note no XPath da linha 6 que as duas barras "//" estão repetidas. Na primeira vez ela simboliza a busca por um elemento em qualquer parte da página. Na segunda, ela representa uma busca entre todos os filhos do que foi encontrado antes.
Ou seja, "//section[@data-key='esporte'] encontra elementos "section" e "//h3[@class='title__element headlineSub__content__title']" encontra elementos "h3" dentre todos os filhos dos elementos "section" encontrados.
Depois de encontrado o elemento, na linha 9 basta usar .text para obter o texto que está sendo exibido, no caso uma manchete.
As manchetes encontradas foram:
O que desgastou Rubão e Augusto no Corinthians? Ex-diretor dá sua versão
Textor vira argumento para reclamações generalizadas; STJD retoma hoje julgamento
Ginástica artística do Brasil pula na frente e vira alvo de outros países